Habíamos visto como instalar Elasticsearch y Kibana en la anterior entrada. Ahora vamos a realizar alguna búsqueda para ver cómo se comporta Elasticsearch. Se puede hacer mediante curl creando un índice y metiendo a mano diversos documentos, pero eso no sirve para gran cosa y es mejor enfocarse en algún caso práctico.
Es importante primero aclarar algún concepto. Elasticsearch llama índice a un sitio donde se almacenan documentos y permite hacer búsquedas muy eficientes. Como se puede ver no tiene nada que ver con el concepto índice de bases de datos. De hecho, un índice sería equivalente a una tabla de base de datos. Si un índice contiene documentos, ¿qué es un documento? Pues bien, un documento es una recopilación de campos, los que, a su vez, son pares de clave-valor que contienen tus datos. Cada índice es único y cada documento dentro de un índice también.
Dejamos la anterior entrada parando los contenedores. Ahora los ponemos en marcha de nuevo:
$ sudo docker container start es01 kib01Se comprueba si están los puertos necesarios escuchando
$ ss -ltn|egrep '5601|9200'Y debería verse:
LISTEN 0 4096 0.0.0.0:9200 0.0.0.0:*
LISTEN 0 4096 0.0.0.0:5601 0.0.0.0:*
LISTEN 0 4096 [::]:9200 [::]:*
LISTEN 0 4096 [::]:5601 [::]:*Nos conectamos vía web a la URL http://192.168.1.215:5601, ingresamos usuario y contraseña y se nos mostrará el dashboard con las distintas opciones:
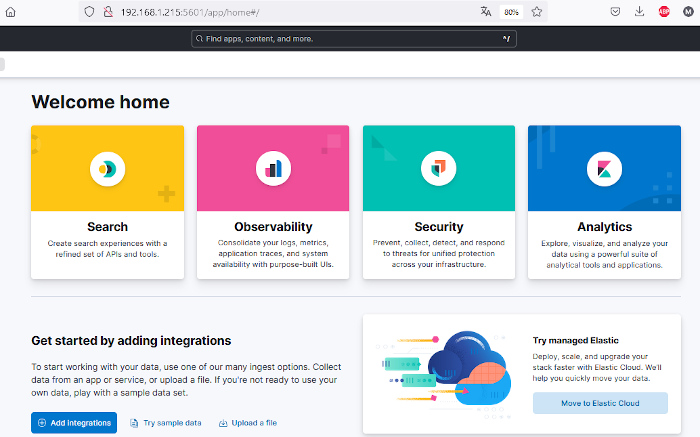
Haremos clic en «Search» y se nos mostrará una página con información sobre la búsqueda y diversos métodos para crear índices y alimentar dichos índices con documentos. En la parte izquierda existe un menú vertical con diversos ítems como Content, Indices, Connectors, Web crawlers, etc.
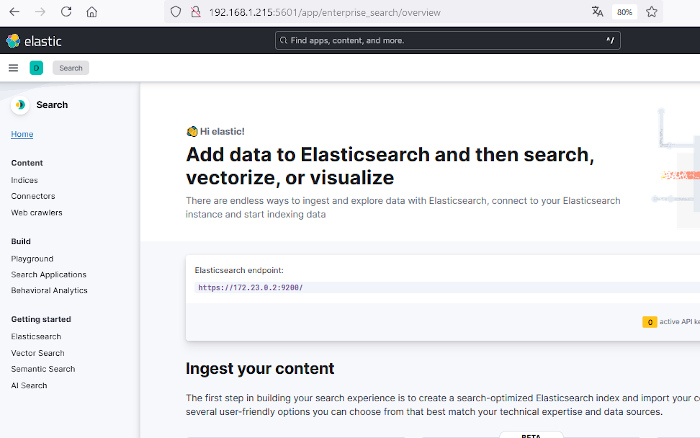
Seleccionaremos Connectors para crear un conector.
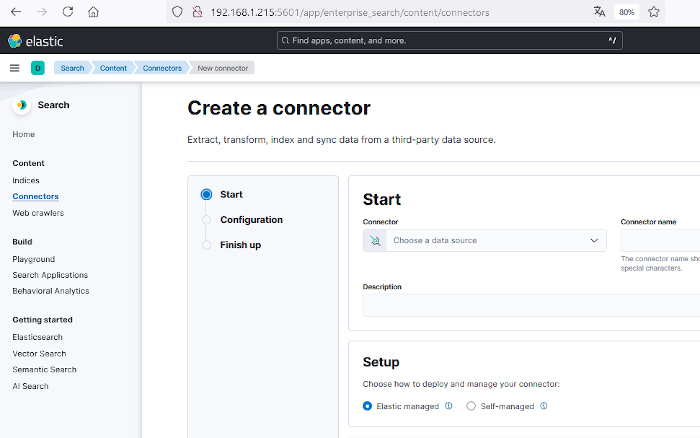
Utilizaremos un conector para consultar una base de datos MySQL y obtener la información de una determinada base de datos. Para ellos en el desplegable «Choose a data source» se seleccionará el conector MySQL y se le dará un nombre, por ejemplo, mysql-connector-wordpress y si se quiere, una descripción del conector. Se seleccionará además «Elastic managed» ya que de esta forma no es necesario desarrollar un método de alimentar el índice.
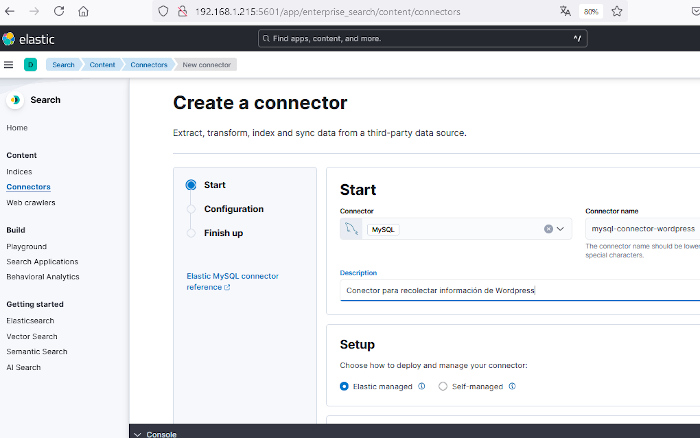
En esa misma página, algo más abajo se hará clic en el botón «Generate configuration» y se generarán tres cosas: un índice, un conector y lo que llaman «API key» que es una clave para poder conectarse al motor de búsqueda desde el conector. Es importante guardar en un lugar seguro esa API key aunque puede volver a generarse en caso de pérdida.
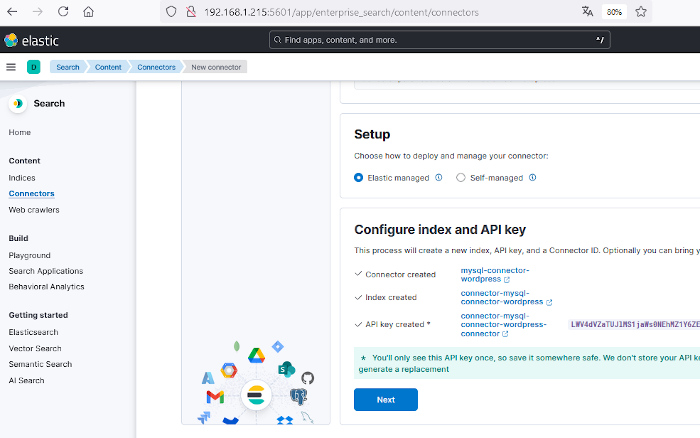
Una vez se tenga, se hará clic en el botón «Next» para continuar con la configuración del conector. En esa página se introducirán los parámetros para conectarse al servidor MySQL. Eso ya depende de la configuración de cada cual. En el caso de ejemplo el servidor de base de datos está en un equipo con IP 192.168.1.212, el puerto es el estándar de MySQL, el 3306 y el usuario y la base de datos coinciden, pero lo normal es que sean distintos. Dentro de la base de datos puede haber varias tablas. En este ejemplo pondremos * para que obtenga los datos de todas las tablas que encuentre en esa base de datos.
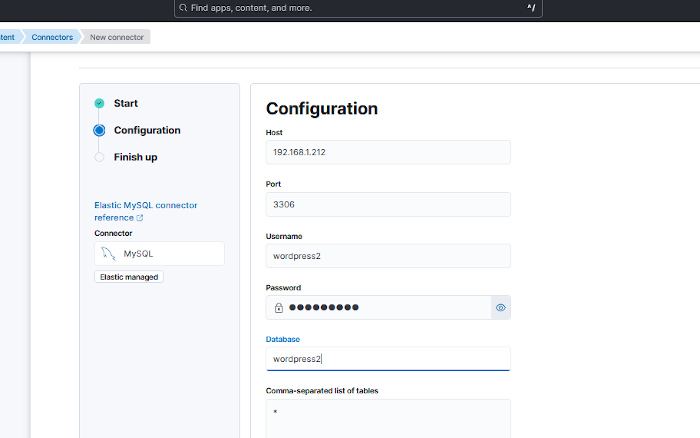
Una vez se haya configurado el acceso al servidor se hará clic en el botón «Next» que está algo más abajo en ese misma página.
Al tratar de hacer una sincronización y ver los documentos generados, se verá un aviso indicando que no se permiten conectores nativos fuera de la nube de Elastic, es decir, que si no sueltas la pasta no se pueden utilizar los conectores nativos y hay que convertirlos en conectores autogestionados. Para ello haremos clic en el botón amarillo «Convert connector».
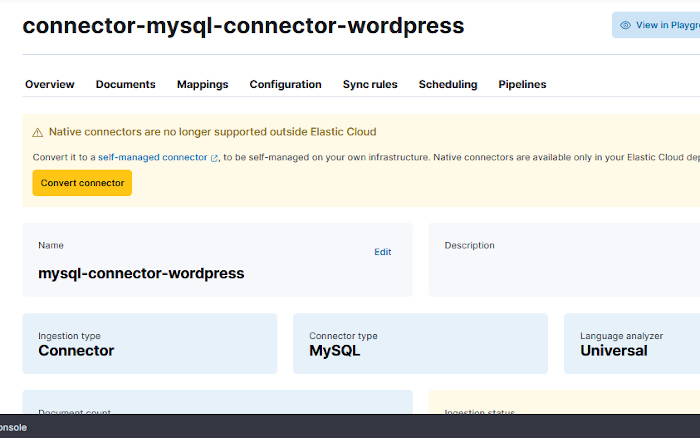
Al hacer clic en el botón nos dirá que esa acción no se puede deshacer. Aún así diremos que sí y al hacerlo podemos ver en la pestaña de Configuración que ya es un conector autogestionado.
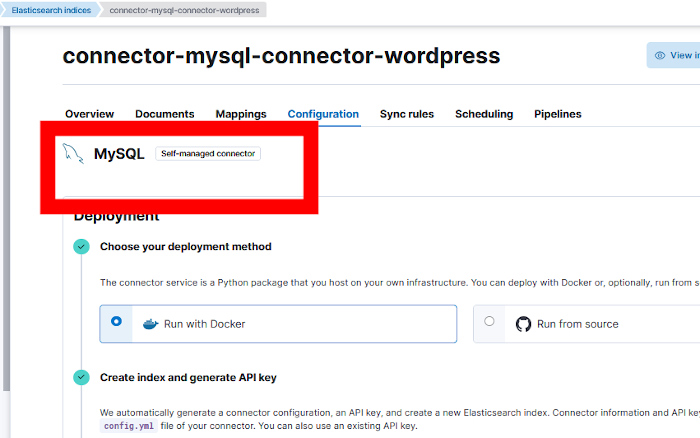
Para desplegar el conector se pueden seguir las instrucciones de la página https://github.com/elastic/connectors/blob/8.16/docs/DOCKER.md que haremos aquí paso a paso.
Se creará un directorio donde se guardará la configuración del conector. Como ejemplo se creará el directorio connectors-config en el directorio home del usuario.
$ cd ~ && mkdir connectors-configDentro de ese directorio se creará un fichero de configuración llamado config.yml con el contenido:
$ cat config.yml
connectors:
-
connector_id: "I8auWJMBSA8KzaEkE7PE"
service_type: "mysql"
api_key: "OUliZGRwTUIyNTB0aDVZOTRiYVc6Y3lXQ3dHR09RbTZJWFlwN0lxWFNHUQ=="
elasticsearch:
host: "https://192.168.1.215:9200"
api_key: "OUliZGRwTUIyNTB0aDVZOTRiYVc6Y3lXQ3dHR09RbTZJWFlwN0lxWFNHUQ=="
ca_certs: "/config/http_ca.crt"Obviamente, el connector_id y la api_key varían de un conector a otro, son datos que se sacarán de la configuración del conector que se ha generado.
Dos cosas importantes que me dieron más de un dolor de cabeza. Por defecto aparece por todos lados que host es «http://localhost:9200». Pues bien, en mi caso no funcionaba y tuve que cambiar localhost por la IP del servidor donde está corriendo elasticsearch. En mi caso la IP 192.168.1.215. Y también es fundamental añadir el certificado con la clave «ca_certs». Ese certificado se copia de la configuración de elasticsearch del docker que se está ejecutando:
$ cd ~/connectors-config
$ sudo docker cp es01:/usr/share/elasticsearch/config/certs/http_ca.crt .Con la configuración y el certificado, ya se puede lanzar el docker con Es un fichero con todas las líneas comentadas, hay que tocar algunas para que funcione el conector. Una de las cosas que se necesitan es la API KEY que se generó cuando se configuró el conector. Si no se copió en un sitio seguro se puede volver a generar
$ sudo docker run -v "$HOME/connectors-config:/config" --tty \
--rm docker.elastic.co/integrations/elastic-connectors:8.16.1 \
/app/bin/elastic-ingest -c /config/config.ymlLa primera vez que se lanza no encontrará la imagen del contenedor:
Unable to find image 'docker.elastic.co/integrations/elastic-connectors:8.16.1' locallyPor lo que hará un pulling para bajarla:
8.16.1: Pulling from integrations/elastic-connectorSi todo ha funcionado bien, debería verse algunos mensajes de que está todo ok:
[FMWK][08:08:04][INFO] Running connector service version 8.16.1
[FMWK][08:08:04][INFO] Loading config from /config/config.yml
[FMWK][08:08:04][INFO] Running preflight checks
[FMWK][08:08:04][INFO] Waiting for Elasticsearch at https://192.168.1.215:9200 (so far: 0 secs)
[FMWK][08:08:04][INFO] Elasticsearch 8.16.1 and Connectors 8.16.1 are compatible
[FMWK][08:08:04][INFO] Extraction service is not configured, skipping its preflight check.
[FMWK][08:08:04][INFO] [job_scheduling_service] Job Scheduling Service started, listening to events from https://192.168.1.215:9200
[FMWK][08:08:04][INFO] [content_sync_job_execution_service] Content sync job execution service started, listening to events from https://192.168.1.215:9200
[FMWK][08:08:04][INFO] [access_control_sync_job_execution_service] Access control sync job execution service started, listening to events from https://192.168.1.215:9200
[FMWK][08:08:05][INFO] [Connector id: I8auWJMBSA8KzaEkE7PE, index name: connector-mysql-connector-wordpress] Successfully connected to the MySQL Server.Se hará clic en el botón Sync situado en la parte baja de la pestaña Configuration…
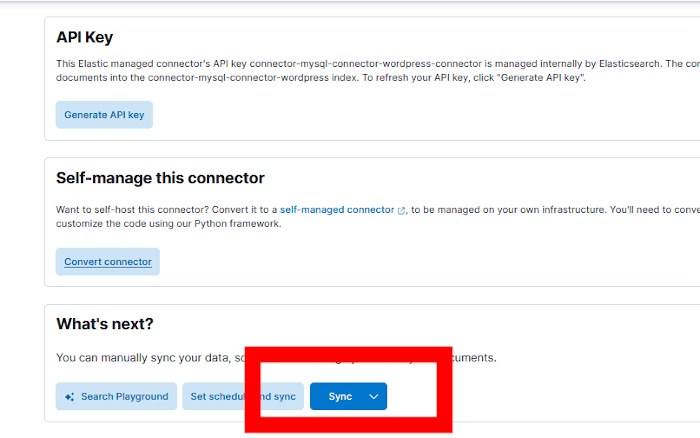
Y en la consola de comandos se debería ver cómo se va sincronizando:
[FMWK][08:13:12][INFO] [Connector id: I8auWJMBSA8KzaEkE7PE, index name: connector-mysql-connector-wordpress, Sync job id: 9ob5dpMB250th5Y9vrZS] Sync progress -- created: 19100 | updated: 0 | deleted: 0
[FMWK][08:13:12][INFO] [Connector id: I8auWJMBSA8KzaEkE7PE, index name: connector-mysql-connector-wordpress, Sync job id: 9ob5dpMB250th5Y9vrZS] Sync progress -- created: 19200 | updated: 0 | deleted: 0
[FMWK][08:13:12][INFO] [Connector id: I8auWJMBSA8KzaEkE7PE, index name: connector-mysql-connector-wordpress, Sync job id: 9ob5dpMB250th5Y9vrZS] Sync progress -- created: 19300 | updated: 0 | deleted: 0
[FMWK][08:13:12][INFO] [Connector id: I8auWJMBSA8KzaEkE7PE, index name: connector-mysql-connector-wordpress, Sync job id: 9ob5dpMB250th5Y9vrZS] Sync progress -- created: 19400 | updated: 0 | deleted: 0Al acabar la conexión nos mostrará un resumen de lo que ha hecho:
[FMWK][08:13:22][INFO] [Connector id: I8auWJMBSA8KzaEkE7PE, index name: connector-mysql-connector-wordpress, Sync job id: 9ob5dpMB250th5Y9vrZS] full counters dictionary: {'docs_extracted': 22968, 'doc_creates_queued': 22968, 'bulk_operations.index': 22968, 'bulk_item_responses.index': 22968, 'result_successes': 22949, 'indexed_document_count': 22949, 'indexed_document_volume': 67, 'deleted_document_count': 0, 'bulk_item_responses.result_errors': 19}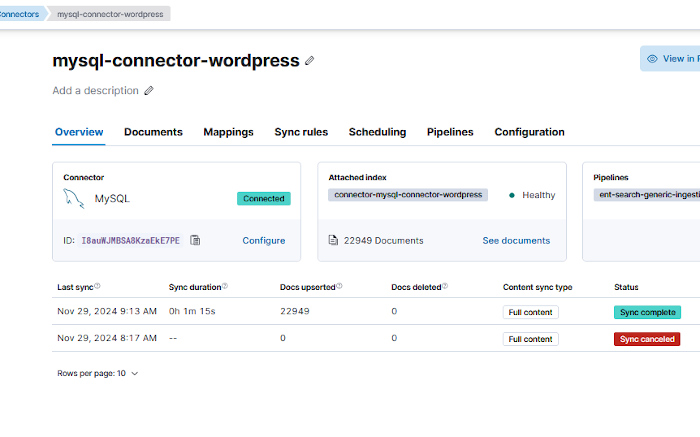
Efectivamente lo que se ve en la consola de comandos coincide con lo que se ve en la web. Nada menos que 22.949 documentos. La web de la que se han sacado los datos tiene algo más de 1.800 entradas, algo sobre ahí entonces.
Mirando los diversos documentos veo que algunos tienen el prefijo wp_posts_ y luego un número, que es distinto para cada entrada. Otros documentos tienen otro prefijo, por ejemplo, wp_options_. Esto es debido a que Elasticsearch utilizar el nombre de las diversas tablas (wp_posts, wp_options) para generar los nombres de los documentos. En el ejemplo sólo nos interesa la información de las distintas entradas de esa web, por lo que se puede restringir la ingesta de información a sólo una tabla, a la tabla wp_posts que es la que contiene las entradas.
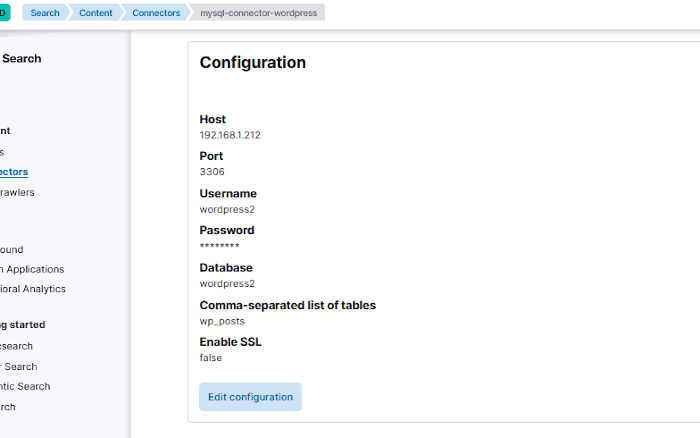
Si se lanza de nuevo una sincronización total…
[FMWK][08:11:43][INFO] [Connector id: I8auWJMBSA8KzaEkE7PE, index name: connector-mysql-connector-wordpress, Sync job id: -IZshpMB250th5Y9MrYD] full counters dictionary: {'docs_extracted': 5722, 'doc_updates_queued': 5703, 'doc_creates_queued': 19, 'doc_deletes_queued': 17246, 'bulk_operations.index': 5722, 'bulk_item_responses.index': 5722, 'bulk_item_responses._id_duplicates': 5703, 'result_successes': 22949, 'indexed_document_count': 5703, 'indexed_document_volume': 36, 'deleted_document_count': 17246, 'bulk_item_responses.result_errors': 19, 'bulk_operations.delete': 17246, 'bulk_item_responses.delete': 17246}La consola nos dice que ha borrado 17.246 documentos y que hay 5.703. Aún siguen siendo muchos. «Buceando» en los distintos documentos generados por Elasticcsearch, veo que algunos tienen el atributo post_type con el valor «publish» y otros con el valor «revision». Esto indica que todas las revisiones de las diversas entradas, según se van escribiendo y salvando, se guardan también en la base de datos, por lo tanto esas revisiones sobran. También los distintos adjuntos aparecen en esas tablas teniendo el atributo post_type con el valor «attachment». Ahora bien, ¿Cómo se pueden eliminar en la ingesta de información esas entradas de la base de datos?
Para ello Elasticsearch tiene unas reglas de sincronización. Por defecto, al crear el conector sólo hay una única regla que dice «incluir todo». Ahora se pueden crear dos reglas que excluyan aquellos documentos que tengan un atributo llamado post_type con valor «revision» y aquellos cuyo post_type sea «attachment»
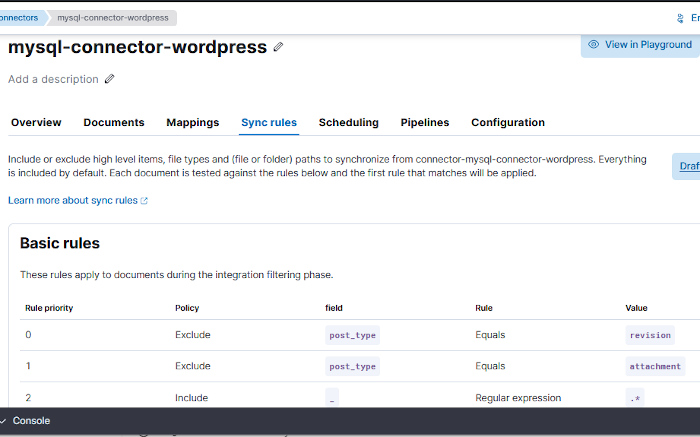
Lanzando una vez más una sincronización total, se obtendrán 1.842 documentos que coinciden más o menos con las entradas de la web. ¡Objetivo conseguido!
